Page Authority 2.0: An Update on Testing and Timing
By rjonesx.
Posted by rjonesx.
One of the most difficult decisions to make in any field is to consciously choose to miss a deadline. Over the last several months, a team of some of the brightest engineers, data scientists, project managers, editors, and marketers have worked towards a release date of the new Page Authority (PA) on September 30, 2020. The new model is exceptional in nearly every way to the current PA, but our last quality control measure revealed an anomaly that we could not ignore.
As a result, we’ve made the tough decision to delay the launch of Page Authority 2.0. So, let me take a moment to retrace our steps as to how we got here, where that leaves us, and how we intend to proceed.

Seeing an old problem with fresh eyes
Historically, Moz has used the same method over and over again to build a Page Authority model (as well as Domain Authority). This model’s advantage was its simplicity, but it left much to be desired.
Previous Page Authority models trained against SERPs, trying to predict whether one URL would rank over another, based on a set of link metrics calculated from the Link Explorer backlink index. A key issue with this type of model was that it couldn’t meaningfully address the maximum strength of a particular set of link metrics.
For example, imagine the most powerful URLs on the Internet in terms of links: the homepages of Google, Youtube, Facebook, or the share URLs of followed social network buttons. There are no SERPs that pit these URLs against one another. Instead, these extremely powerful URLs often rank #1 followed by pages with dramatically lower metrics. Imagine if Michael Jordan, Kobe Bryant, and Lebron James each scrimaged one-on-one against high school players. Each would win every time. But we would have great difficulty extrapolating from those results whether Michael Jordan, Kobe Bryant, or Lebron James would win in one-on-one contests against each other.
When tasked with revisiting Domain Authority, we ultimately chose a model with which we had a great deal of experience: the original SERPs training method (although with a number of tweaks). With Page Authority, we decided to go with a different training method altogether by predicting which page would have more total organic traffic. This model presented several promising qualities like being able to compare URLs that don’t occur on the same SERP, but also presented other difficulties, like a page having high link equity but simply being in an infrequently-searched topic area. We addressed many of these concerns, such as enhancing the training set, to account for competitiveness using a non-link metric.
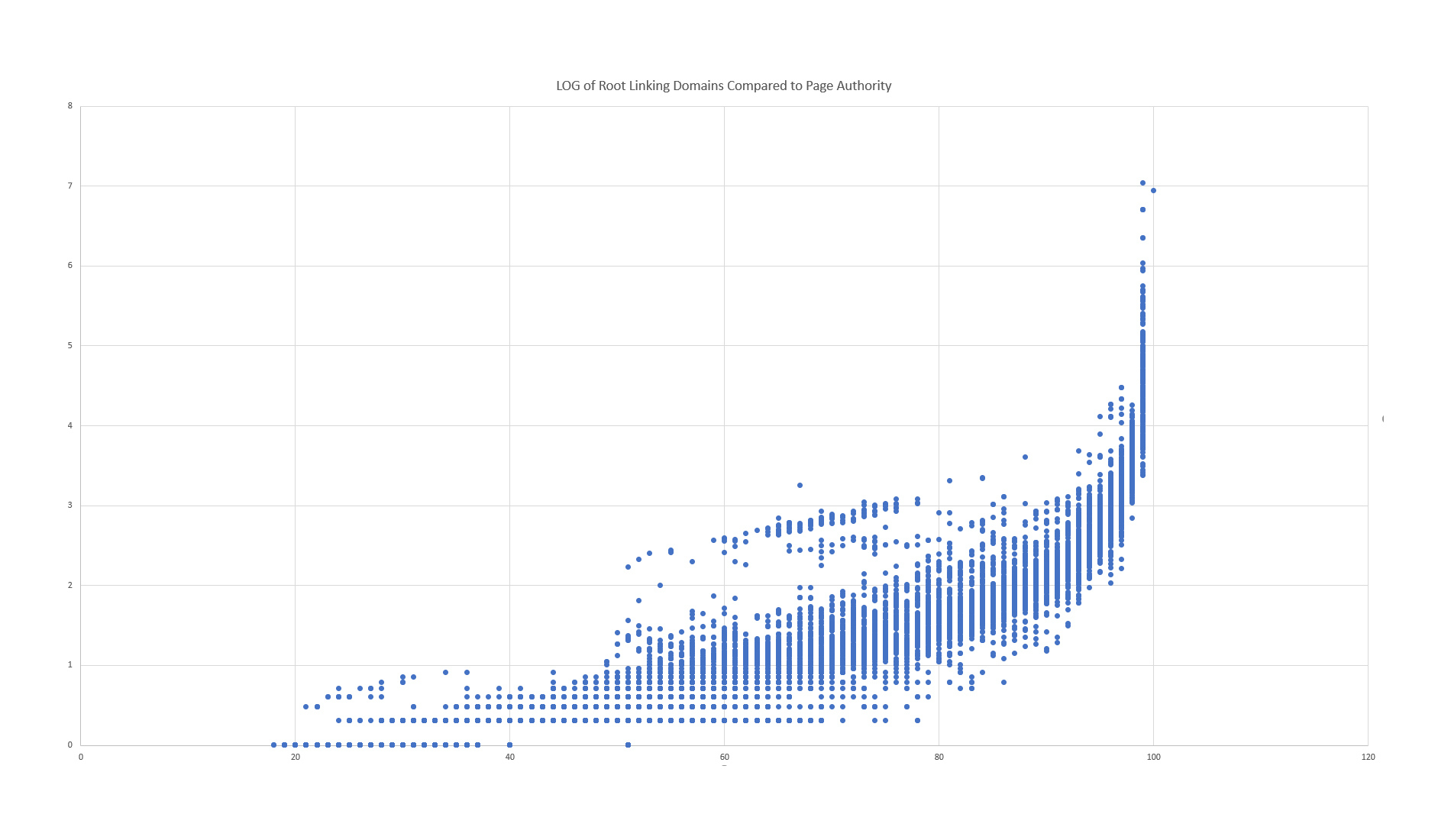
Measuring the quality of the new Page Authority
The results were — and are — very promising.
First, the new model obviously predicted the likelihood that one page would have more valuable organic traffic than another. This was expected, because the new model was directed at this particular goal, while the current Page Authority merely attempted to predict whether one page would rank over …read more

Source:: Moz Blog